
イベント[クローリングのスペシャリストが語る、クローラー運用の裏側]の資料公開
ちょっと前のイベントになりますが、横浜関内のmassmassフーチャーセンターにて「クローリングのスペシャリストが語る、クローラー運用の裏側」というイベントを実施し、壇上させていただきました。

今回は、その時発表した「検索のスピードアップ」の資料と内容をご紹介します!
資料はスライドシェアにアップしてありますのご自由にご覧ください。

今回のイベントの経緯
このイベントは"Bayside Tech Bridge"が運営するイベントの1つです。

今後もエンジニアやデザイナーといったテクノロジーに関わる全ての方々に向けたイベントや情報を共有していきます。
横浜を中心に活動しておりますので、毎月もくもく勉強会をしておりますので、興味のある方はお気軽にご参加ください。
「検索のスピードアップ」
私が発表させていただいた内容は題名の通りで、検索のスピードアップにおけるポイントです。
今回はポイントを3つに絞りました。
クロールとAPI
どこでスピードアップ?
解析処理でスピードアップするポイント
この辺のポイントを掻い摘んでご紹介します。
1. クロールとAPI
WEB上のデータを取ってくる時は、HTML検索かAPI検索の2パターンがほとんどです。
ここでのポイントは、
"APIを積極的に使い検索をスピードアップしましょう"という事です。
APIを使うメリットは大きいです。
速い
レウアウト変更がない
API側で何らかのアクションがある場合は連絡が来る
現在では、ほんとに色んな企業がAPIを提供してくれています。
もし、あなが欲しいデータがあり、これからクロールを行おうとしているなら、まずAPIが存在するか確認して下さい。
そしてAPIが提供されているならAPIを使いましょう!
2. どこでスピードアップ?
検索を行う際には、検索を行う一連の流れがあります。
データ取得から始まり
データの解析処理
DBやストレージへの保存
検索のスピードアップを行おうとした時は、これらの処理ごとにスピードアップさせる方法は違ってきます。
また、それぞれの方法によって工数や費用も違います。
例えば、データ取得の場合は、
サーバーの増設
検索処理の並列に実行する並列化
データの解析処理であれば
開発言語の選択
解析ライブラリの模索
最後のDBやストレージへの保存だと、
DBのチューニングや最適化
キャッシュサーバー、インメモリーデータストアの導入
など、各セクションによってスピードアップ方法や、導入コスト、作業工数や難易度もバラバラです。
ご自分の検索システムをスピードアップさせる場合には、どの部分で検索スピードをアップさせるがベストなのかを確認しましょう!

3. 解析処理でスピードアップするポイント
では実際にスピードアップを行う際に、比較的簡単にスピードアップできるテクニックをご紹介します。
具体的には、"SAX"という解析手法を使います。API検索をする際には特に有効です。

最近の解析ツールはすごい便利で、簡単に導入して解析処理を行うことができます。
XPATHやCSSセクタを指定すればデータを取得できちゃいます。
が、遅いんですよね。
これは解析ツールの仕組みがボトルネックになっています。
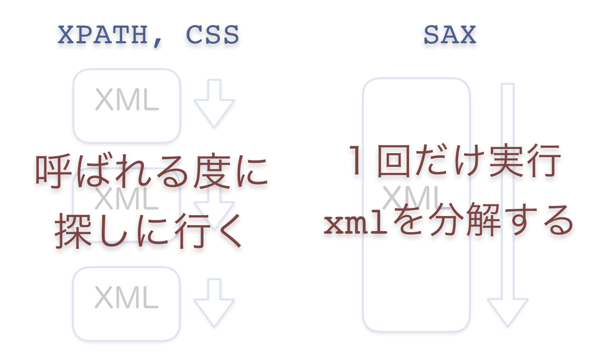
ほとんどのツールがそうだと思いますが、XPATHやCSSセクタで指定する度にXMLソースを最初から検索します。
例えば、こんなXMLがあったとします。
<XML> <data> <hoge1>fuga1</hoge1> <hoge2>fuga2</hoge2> <hoge3>fuga3</hoge3> </data> </xml>
これをCSSセクタ検索するとこんな感じになります。
"hoge1"を取得する → 解析ツールは
タグから読み、次にタグ、でようやく タグに辿り着きます。 "hoge2"を取得する → 解析ツールはまた最初の
タグから読み込みを開始します。
これが遅い原因です。
これを解消できるのがSAXです。
SAXの場合は上から下まで順に実行されます。
SAXでXMLを読み込む
hoge1タグの取得イベントが発生
hoge2タグの取得イベントが発生
といった具合にXMLを呼び込んだ順にデータを取得する事が可能になり、結果大幅なスピードアップを実現できます。
まとめ
使えるならAPIを使おう
どこをスピードアップさせるか見極めよう
XML解析ならSAXもありだよ。
検索するシステムは様々で、世の中の色んな場面で活用されています。
あなたもご自身の検索システムのスピードアップにチャレンジされては如何でしょうか?


コメント